4차 산업혁명시대에 산업 생태계가 급격히 변화하는 시점에서 빠른 연구개발(R&D) 및 사업화를 위한 제조업계의 디지털 전환은 경쟁력 향상을 넘어 생존 문제로 직결되고 있다. 이미 해외 선진국들은 컴퓨터 시뮬레이션을 통한 가상 제조기술 및 인공지능(AI)과 빅데이터 등을 활용한 오픈 플랫폼을 구축해 활용하고 있는 반면 우리나라는 데이터 축적부터 어려움을 겪고 있는 상황이다.
한국생산기술연구원에서는 5년여 동안 내·외부 전문가 학습, 단계별 기술 자체개발 및 검증을 통해 지속적으로 개선되고 있는 제조분야 인공지능 기술을 바탕으로 중소·중견기업의 제조업 인공지능 기술적용을 위한 연구를 해왔다. 본지는 이러한 연구결과를 총 10회에 걸친 연재기고를 통해 제조공정에 인공지능을 적용하기 위한 방법을 전달하고자 한다. 이를 통해 보다 많은 기업들이 쉽고 편하게 데이터 취득시스템을 개발·설치하고, 데이터 입출력 부분을 셀프 코딩하며, 송수신, 데이터 전처리 등을 거친 효과적인 인공지능 알고리즘을 통한 학습 및 검증을 통해 자사의 문제들을 풀어감으로써 제조기술 지능화에 한 발짝 다가가길 기대한다.
시계열 데이터의 특징과 전처리 방법 및 용접불량 예측 예시
스패터 발생량 용접파형 통해 예측, 데이터 특성 따라 정확도 향상 가능
■연재 순서
1. 제조 중소·중견기업 인공지능 기술개발
2. 제조공정 데이터 취득(DAQ) 시스템 개발
3. IoT 센서 패키지 HW/SW 개발 및 데이터 송·수신
4. 데이터 전처리
5. 제조업 인공지능 적용
6. 인공지능 데이터 및 알고리즘 유형
7. 디지털 트윈 구축 및 HW/SW 개발 적용
8. 시계열 데이터 인공지능 학습 (예)
9. 이미지 데이터 인공지능 학습 (예)
10. 뿌리 제조기업의 공정지능화 과제

■제조현장의 공정 데이터와 불량 예측
제조현장에서 공정을 제어하거나 품질을 평가하기 위하여 수집되는 대표적인 데이터 형태로 시계열 데이터와 이미지 데이터가 있다.
시계열 데이터는 일정 시간간격으로 순차적으로 수집되는 데이터의 집합이고 이미지 데이터는 사진 또는 동영상의 형태를 가진다. 제조현장에서 주로 수집되는 시계열 데이터는 센서를 통해 얻어지는 온도, 습도, 압력과 같은 특성 값 혹은 전류, 전압과 같은 전기신호가 있다.
일반적으로는 이러한 데이터 값을 모니터링하면서 정상으로 판단하는 데이터의 상하한선을 벗어나는 값이 탐지되는지 검토하여 공정의 안정성을 판단한다.
하지만 어떠한 데이터는 특정 시간대의 데이터가 가지는 값 자체보다도 앞뒤 값들과의 변화량이 중요한 특성이 되기 때문에, 앞서 말한 방법으로는 원하는 정확도의 불량검출율을 달성하기가 어렵다. 이러한 문제를 해결하기 위해 데이터들이 특정 시간동안 그리는 패턴을 AI를 통해 학습하여 기기의 이상 유무나 제품의 불량발생 유무를 예측하는 방법들이 제시되고 있다.
■시계열데이터의 전처리 기법
이산형 데이터(두께, 무게 등 시간의 변화와 상관없는 데이터)와 달리 시계열 데이터는 길이를 가진다. 물론 두께나 무게도 시간에 따라 연속적으로 변하는 경우, 이를 주기적으로 수집을 하면 시계열 데이터가 되기는 하지만 말이다.
시계열 데이터의 길이는 수집시간에 따라, 샘플주파수에 따라 달라지지만 샘플주파수가 높고 측정시간이 길수록 측정하는 데이터의 특성의 손실이 작아지므로 AI학습을 위해서는 일반적으로 수십에서 수십만 수준의 길이가 긴 시계열 데이터를 다루게 된다. 후술하겠지만, 시계열 데이터를 다루는 대표적인 AI알고리즘은 다른 종류의 데이터를 다루는 AI알고리즘보다 학습효율이 좋지 못하다. 또 순차적인 데이터를 다루는 알고리즘은 사람과 유사하게 데이터 길이가 길어질수록 앞서 입력받은 데이터에 대한 기억을 잊어버리게 된다.
따라서 같은 크기의 데이터를 다루더라도 시계열 데이터의 학습은 시간이 더 오래 걸릴 뿐 아니라 데이터의 길이가 길어질수록 데이터 앞단에 위치한 정보에 대한 학습효과가 심각하게 나빠지게 된다.
때문에, 긴 길이의 시계열 데이터를 직접적으로 학습시키는 것은 매우 비효율적이며 보통 지금부터 설명하는 전처리 방법을 통해 데이터가 가진 특성은 살리되 데이터의 크기는 축소시키는 작업을 먼저 수행하게 된다.(데이터 전처리 관련하여 이전 연재내용에서 서술된 바 있는 데이터의 결측치, 특이치, 노이즈 제거 등에 대한 내용은 생략하였으나, 다음의 전처리 방법을 수행하기 전에 이러한 데이터 클리닝이 완료되어야 한다.)
▷다양한 신호처리 방법: 기존에 잘 알려진 디지털 신호처리 기법을 활용한다. 예를 들어 특정 시간단위로 데이터의 통계적 특징을 추출하는 방법이 있다. 통계적 특징으로는 평균(mean), 분산(variance), 왜도(skewness), 첨도(kurtosis) 등이 있다. 초당 1,000개의 샘플을 가지는 1분짜리 데이터를 1000개의 샘플의 통계적 특징을 추출하여 압축하면 길이 60,000의 데이터를 길이 60의 데이터로 줄일 수 있다.
또 다른 대표적인 신호처리 방법으로는 푸리에 변환(FFT) 방법이 있다. 푸리에 변환은 시간영역의 데이터를 주파수 영역의 데이터로 변환해주는 방법으로, 데이터 특성에 따라 데이터의 특성 손실은 최소화 하면서 데이터 압축률을 매우 높일 수가 있다. 비슷한 변환 방법으로는 웨이블렛 기술이 있다.
▷이미지 변환 방법: 이미지 기반의 AI 기술이 매우 좋은 성능을 보여주면서 시계열 데이터역시 이미지화를 통해 이미지 기반의 AI 기술을 적용하는 사례가 늘고 있다. 시계열 데이터를 이미지화하는 방법으로는 Gray Scale Encoding, Gramian Angular Field, Markov Transition Field등이 있고 특히 주기성과 주파수에 대한 특징을 잡아내기 위한 이미지 변환방법으로는 Recurrence Plot, Spectrogram, Scalogram 등이 있다.
 ▲ <그림1>시계열 데이터의 여러 가지 이미지 변환 방법(이미지 출처:Garcia GR et al. Temporal signals to images: Monitoring the condition of industrial assets with deep learning image processing algorithms. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk
▲ <그림1>시계열 데이터의 여러 가지 이미지 변환 방법(이미지 출처:Garcia GR et al. Temporal signals to images: Monitoring the condition of industrial assets with deep learning image processing algorithms. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk
■시계열 데이터 처리를 위한 AI알고리즘
시계열 데이터를 학습시키는데 가장 대표적인 AI알고리즘은 순환신경망(RNN, Recurrent Neural Network)이다. 일반적인 신경망 모델은 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)로 구성되어, 은닉층을 통과한 입력은 출력층으로만 전파된다.
하지만 순환신경망은 은닉층을 나온 값들이 다시 은닉층으로 들어가 그 다음 순차의 데이터와 함께 처리된다. 때문에, 앞서 지나온 데이터에 대한 영향이 은닉층에 쌓여 순차적인 데이터의 연결성이 네트워크에 반영된다는 장점이 있지만, 데이터를 순차적으로 처리해야하기 때문에 데이터를 병렬로 처리할 수 없어 다른 AI알고리즘 대비 학습효율이 낮다는 단점도 존재한다.
아래 <그림2>는 RNN의 구조를 나타내며 X는 입력, A는 셀(Cell), h는 출력을 의미한다. 가장 왼쪽의 그림은 은닉층을 나온 데이터가 다시 은닉층으로 들어가는 모습을 도식화 한 것으로, 이를 시간단위로 펼쳐 보이면 오른쪽의 그림들처럼 나타낼 수 있다. 이때 셀을 나온 출력이 순차적으로만 전파(Uni-directional) 되지 않고 양방향(전후)으로 전파되는 경우 Bi-directional 모델이라고 한다.
앞서 언급한바와 같이, AI 알고리즘도 사람도 비슷하게 학습이 진행될수록 먼저 입력되었던 데이터를 망각하게 되는데 이를 보완하기 위해 셀에서 입력데이터를 다양한 방법으로 처리하는 알고리즘이 제안되었고, 대표적으로는 LSTM, GRU가 있다.
 ▲ <그림2>순환신경망(RNN, Recurrent Neural Network) 모형
▲ <그림2>순환신경망(RNN, Recurrent Neural Network) 모형
■시계열 제조데이터 학습 사례 (용접)
용접에서 단락이행이란 연속으로 공급되는 용접와이어 끝단에 고온의 아크열로 인하여 용융된 용적이 시간에 따라 성장하여 용융지에 닿으면서 전기적으로 단락되고, 이러한 상태에서 용적이 용융지로 이행되어 가는 것을 말한다.
용적이 이행되면서 가교가 형성되고 가교가 끊어지면서 재 아크가 발생되는데, 이때 아크는 고온이기 때문에 주변공기를 급격하게 팽창시키고 그 폭발력으로 인해 남아 있는 용적이 비산되며, 이를 스패터 (Spatter)라고 한다. 스패터, 특히 대립의 스패터는 주변 모재에 강하게 부착되므로 제거하는데 인력과 시간이 소요되어 용접자동화 및 생산성 향상에 방해가 된다.
따라서 스패터를 줄이는 것이 용접품질을 향상시키기 위해 중요한 기술이고, 또 이를 위해 현장에서 직접 측정이 불가능한 스패터 발생량을 용접파형을 통해 예측하는 기술 역시 중요하다고 할 수 있다. 본 예에서는 용접 단락이행의 스패터 발생량을 용접 조건 (전압, 전류(송급 속도))에 따른 용접파형 데이터를 이용하여 예측하여 보았다.
▷데이터 수집 및 전처리 : 학습에 사용한 데이터셋은 전압조건(100%(정상조건), 120%, 140%)에 따라 4~9m/min의 송급 속도에 대해 1분간 3번씩 반복 실험한 총 54개의 데이터로 구성되어 있으며 발생한 스패터는 크기에 따라 4종류(s1 ≤ 250μm, 250μm ≤ s2 < 500μm, 500μm ≤ s3 < 1000μm, 1000μm ≤ s4)로 분류하였다. 높은 샘플링 수 (700,000/min)로 인해 원본데이터(Raw Data)를 직접 처리하는 것은 너무 많은 시간이 소요되므로 원본데이터를 사용하는 경우와 2가지 전처리 방법을 사용한 경우를 비교하여 보았다.<br>
첫째는 용접파형 데이터를 두 샘플당 한 개씩 사용하여 데이터 크기를 1/2로 축소하여 사용하는 방법이다. 두 번째는 고속 푸리에 변환을 사용하여 높은 진폭을 가지는 1000개의 주파수를 학습데이터로 사용하는 방법이다. 이 경우 1/700으로 데이터를 압축하여 학습효율을 향상시킬 수 있다. 이 때 용접 시작 및 종료 시 불규칙한 신호가 기록된 부분을 삭제하는 등 데이터 클리닝 작업을 선행하였다.
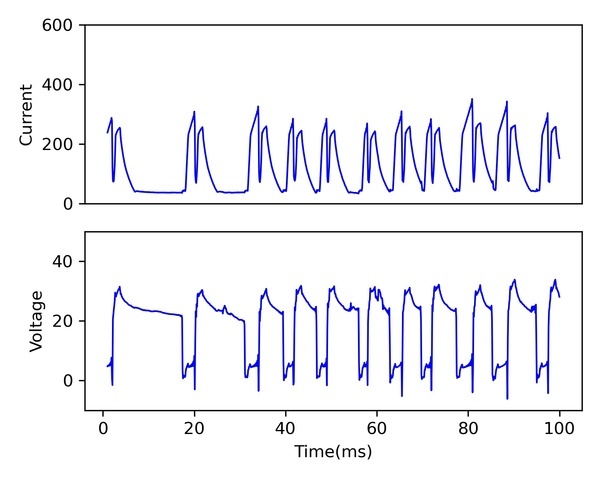 ▲ <그림3>단락이행 용접파형 데이터 예시
▲ <그림3>단락이행 용접파형 데이터 예시
 ▲ <그림4>용접파형 데이터를 FFT처리 후 학습한 경우 학습 히스토리 비교
▲ <그림4>용접파형 데이터를 FFT처리 후 학습한 경우 학습 히스토리 비교
▷학습 및 결과 : 학습모델로는 순환신경망 모델 중 하나인 LSTM을 사용하였다. 모델은 한 층의 단순한 구조이고 데이터가 양방향으로 전파될 수 있도록 Bi-directional모델을 적용하였다. (손실함수, 옵티마이저 및 배치사이즈는 각각 mse, adam, 20을 사용하였다.)
먼저 원본데이터를 이용해 크기별 스패터 발생량(s1~s4)을 각각 예측해보았다. 크기별로 88.1%, 86.0%, 74.9%, 72.9%의 정확도로 예측함을 확인하였다. 다음 스패터 발생량 총합에 대해 전처리 방법에 따른 학습효율 및 예측정확도를 비교해보았다. 샘플링을 통해 데이터를 1/2로 축소한 경우 두 배 이상 빠르게 학습을 진행하는 것이 가능하였고 예측정확도는 약 4% 정도가 감소하였다.
용접파형 데이터를 FFT 처리한 후 학습을 진행한 경우는 학습속도가 1/10이상 감소하였으나 손실함수의 수렴이 2배 이상 나빠지는 것을 확인할 수 있었다. 이는 용접 파형 데이터가 특정 주파수대가 아닌 전반적으로 고른 주파수대에서 발생하고 있기 때문으로 생각할 수 있다.
이 결과만 가지고 어떤 전처리 방법, 혹은 AI모델이 더 적합하다고 이야기하는 것은 어렵고, 데이터 특성에 따라 예측 정확도를 높일 수 있는 전처리 방법 및 AI모델이 있다는 사실만 확인하였으면 한다.
 ▲ <그림5>용접파형 데이터를 FFT처리 후 학습한 경우 학습 히스토리 비교
▲ <그림5>용접파형 데이터를 FFT처리 후 학습한 경우 학습 히스토리 비교